


Intelligently Extract Text & Data from Document with OCR NER
开发文档扫描仪应用程序项目,即从扫描文档中提取命名实体
你会学到:
开发和训练命名实体识别模型
不仅从图像中提取文本,而且从名片中提取实体
从头开始开发像ABBY这样的名片扫描仪
自然语言问题的高级数据预处理技术
实时NER应用程序
MP4 |视频:h264,1280×720 |音频:AAC,44.1 KHz,2 Ch
语言:英语+中英文字幕(云桥CG资源站 机译)云桥CG资源站 |时长:65节课(5h) |大小解压后:1.99 GB 含课程文件

要求
至少应该是Python的初学者
了解熊猫数据帧的聚合技术
使用OpenCV读取、写入图像,并在图像上绘制矩形
描述
欢迎学习“用光学字符识别NER从文档中智能提取文本和数据”课程!!!
在本课程中,您将学习如何开发定制的命名实体识别器。本课程的主要思想是从扫描的文档中提取实体,如发票、名片、发货单、提单文档等。然而,为了数据隐私,我们将我们的观点限制在名片上。但是你可以用这个框架来解释各种财务文件。下面给出的是我们开发项目所遵循的课程。

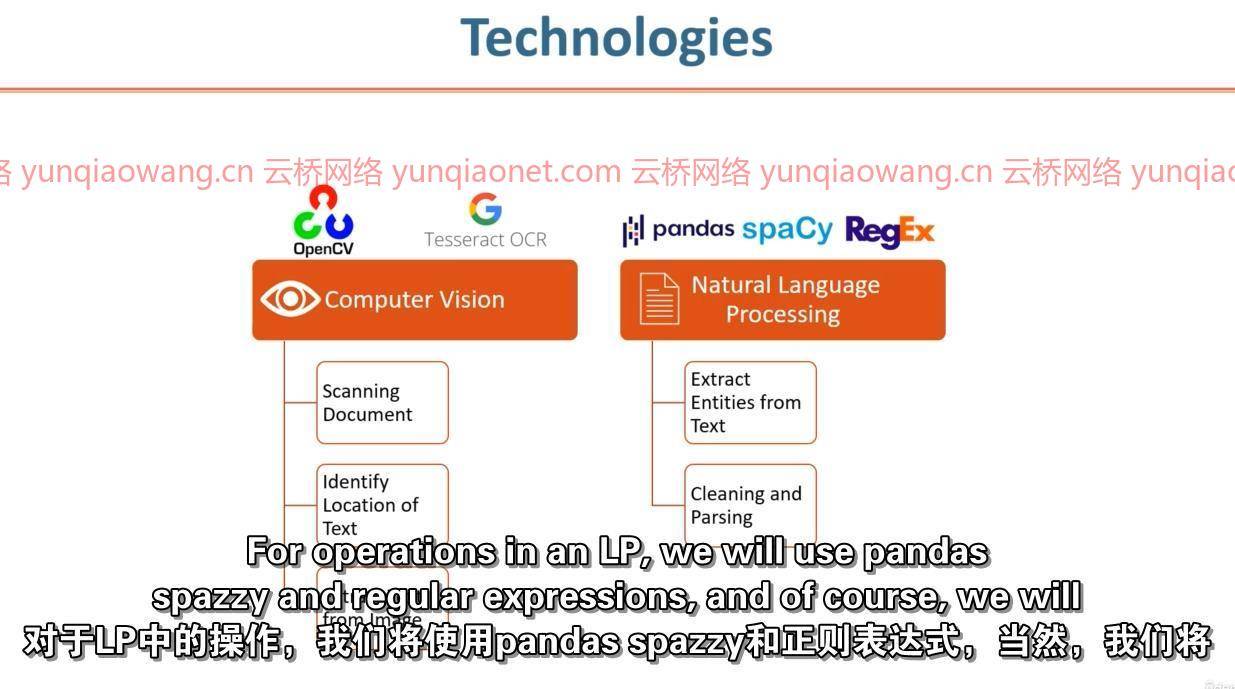
为了开发这个项目,我们将使用数据科学中的两种主要技术,
计算机视觉
自然语言处理
在计算机视觉模块中,我们将扫描文档,识别文本的位置,最后从图像中提取文本。然后在自然语言处理中,我们将从文本中提取实体,进行必要的文本清理,并从文本中解析实体。
计算机视觉模块中使用的Python库。
OpenCV
数字
侏儒怪
自然语言处理中使用的Python库
Spacy
熊猫
正则表达式
线
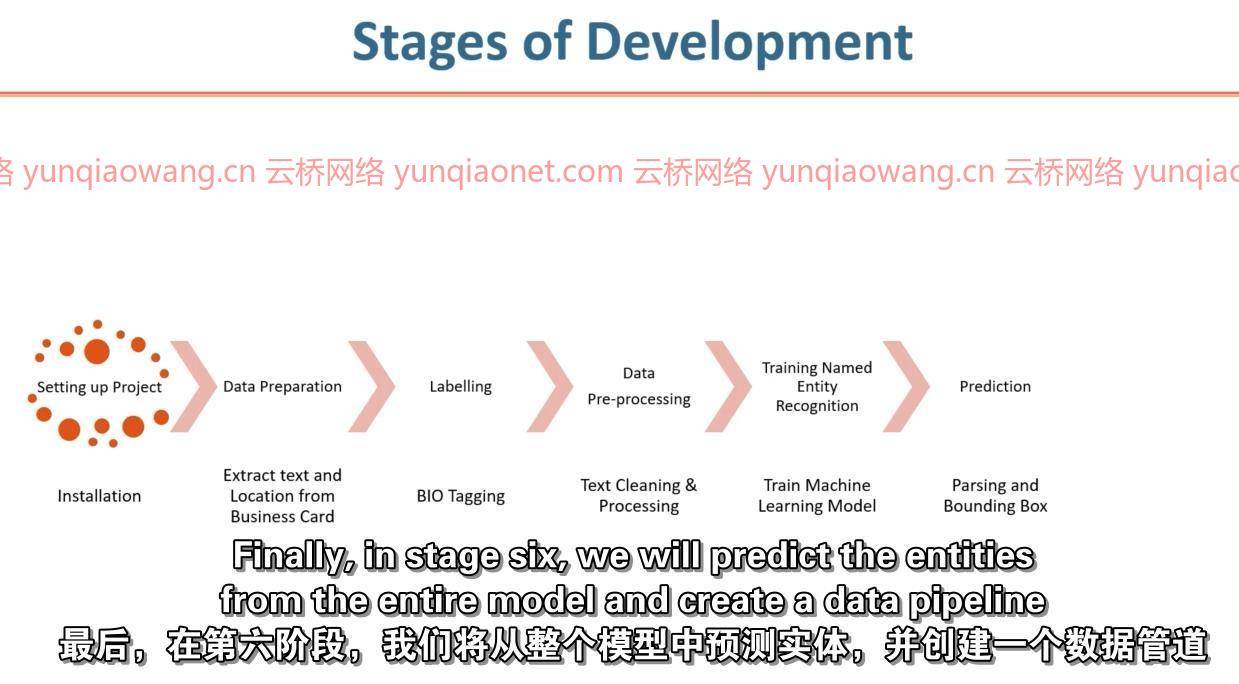
由于我们结合了两种主要技术来开发项目,为了便于理解,我们将课程分为几个开发阶段。
阶段1:我们将通过进行必要的安装和要求来设置项目。
安装Python
安装依赖项
第二阶段:做数据准备。也就是说,我们将使用Pytesseract从图像中提取文本,并进行必要的清理。
收集图像
侏儒怪概述
从所有图像中提取文本
清理和准备文本
阶段3:我们将看到如何使用生物标签来标记NER数据。
用生物技术手工标记
开始
我在里面
外面
阶段4:我们将进一步清理文本并对数据进行预处理,以训练机器学习。
为空间准备培训数据
将数据转换为spacy格式
阶段5:使用预处理数据,我们将训练命名实体模型。
配置NER模型
训练模型
阶段6:我们将使用NER和模型预测实体,并创建用于解析文本的数据管道。
负载模型
用Displacy渲染和服务
在图像上绘制边界框
从文本解析实体
最后,我们将把所有这些放在一起,创建文档扫描仪应用程序。
你准备好了吗!!!
让我们开始开发人工智能项目。
这门课是给谁的
任何想开发名片阅读器应用程序的人
想要提高自然语言处理技能的数据科学家、分析师、Python开发人员
MP4 | Video: h264, 1280×720 | Audio: AAC, 44.1 KHz, 2 Ch
Genre: eLearning | Language: English + srt | Duration: 65 lectures (5h) | Size: 1.61 GB
Develop Document Scanner App project that is Named entity extraction from scan documents with OpenCV, Pytesseract, Spacy
What you’ll learn:
Develop and Train Named Entity Recognition Model
Not only Extract text from the Image but also Extract Entities from Business Card
Develop Business Card Scanner like ABBY from Scratch
High Level Data Preprocess Techniques for Natural Language Problem
Real Time NER apps
Requirements
Should be at least beginner in Python
Understand aggregation techniques with Pandas DataFrames
Read, Write Images with OpenCV and Drawing Rectangles on Image
Description
Welcome to Course “Intelligently Extract Text & Data from Document with OCR NER” !!!
In this course you will learn how to develop customized Named Entity Recognizer. The main idea of this course is to extract entities from the scanned documents like invoice, Business Card, Shipping Bill, Bill of Lading documents etc. However, for the sake of data privacy we restricted our views to Business Card. But you can use the framework explained to all kinds of financial documents. Below given is the curriculum we are following to develop the project.
To develop this project we will use two main technologies in data science are,
Computer Vision
Natural Language Processing
In Computer Vision module, we will scan the document, identify the location of text and finally extract text from the image. Then in Natural language processing, we will extract the entitles from the text and do necessary text cleaning and parse the entities form the text.
Python Libraries used in Computer Vision Module.
OpenCV
Numpy
Pytesseract
Python Libraries used in Natural Language Processing
Spacy
Pandas
Regular Expression
String
As are combining two major technologies to develop the project, for the sake of easy to understand we divide the course into several stage of development.
Stage -1: We will setup the project by doing the necessary installations and requirements.
Install Python
Install Dependencies
Stage -2: We will do data preparation. That is we will extract text from images using Pytesseract and also do necessary cleaning.
Gather Images
Overview on Pytesseract
Extract Text from all Image
Clean and Prepare text
Stage -3: We will see how to label NER data using BIO tagging.
Manually Labeling with BIO technique
B – Beginning
I – Inside
O – Outside
Stage -4: We will further clean the text and preprocess the data for to train machine learning.
Prepare Training Data for Spacy
Convert data into spacy format
Stage -5: With the preprocess data we will train the Named Entity model.
Configuring NER Model
Train the model
Stage -6: We will predict the entitles using NER and model and create data pipeline for parsing text.
Load Model
Render and Serve with Displacy
Draw Bounding Box on Image
Parse Entitles from Text
Finally, we will put all together and create document scanner app.
Are you ready !!!
Let start developing the Artificial Intelligence project.
Who this course is for
Anyone who wants to Develop Business Card Reader App
Data Scientist, Analyst, Python Develop who want to enhance skills in NLP
云桥CG资源站 为三维动画制作,游戏开发员、影视特效师等CG艺术家提供视频教程素材资源!
1、登录后,打赏30元成为VIP会员,全站资源免费获取!
2、资源默认为百度网盘链接,请用浏览器打开输入提取码不要有多余空格,如无法获取 请联系微信 yunqiaonet 补发。
3、分卷压缩包资源 需全部下载后解压第一个压缩包即可,下载过程不要强制中断 建议用winrar解压或360解压缩软件解压!
4、云桥CG资源站所发布资源仅供用户自学自用,用户需以学习为目的,按需下载,严禁批量采集搬运共享资源等行为,望知悉!!!
5、云桥CG资源站,感谢您的赞赏与支持!平台所收取打赏费用仅作为平台服务器租赁及人员维护资金 费用不为素材本身费用,望理解知悉!











