


如何为机器学习模型转换数据集
你会学到什么
如何填补数字和分类变量中的缺失
如何编码分类变量
如何转换数值变量
如何缩放数值变量
主成分分析及其使用方法
如何使用SMOTE应用过采样
如何使用scikit-learn库中的几个有用对象
MP4 |视频:h264,1280×720 |音频:AAC,44.1 KHz,2声道
语言:英语+中英文字幕(云桥CG资源站 机译) |时长:47节课(5小时35分钟)|大小解压后:2.1 GB

要求
Python编程语言的基础知识
描述
在本课程中,我们将重点关注机器学习的预处理技术。
预处理是转换原始数据集以供机器学习模型使用的一组操作。这对于使我们的数据适用于一些机器学习模型、降低维度、更好地识别相关数据以及提高模型性能是必要的。这是机器学习管道中最重要的部分,它能够强烈地影响项目的成功。事实上,如果我们不给机器学习模型提供正确的数据,它根本就不会工作。Data pre-processing for Machine Learning in Python
有时,有抱负的数据科学家开始研究神经网络和其他复杂模型,而忘记研究如何操纵数据集,以便让它们的算法使用它。因此,他们无法创建良好的模型,只有到最后他们才意识到良好的预处理会使他们节省大量时间并提高算法的性能。因此,处理预处理技术是一项非常重要的技能。这就是为什么我创建了一个只关注数据预处理的完整课程。
通过本课程,您将了解到
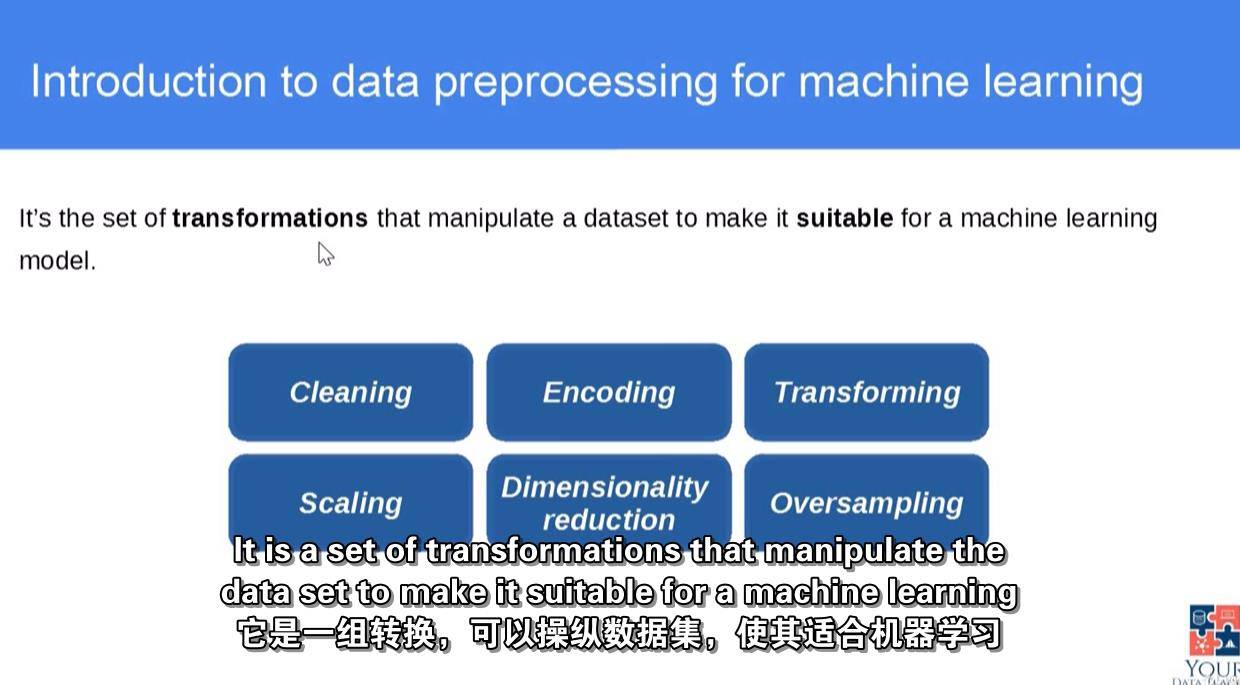
数据清理
分类变量的编码
数字特征的转换
sci kit-学习管道和ColumnTransformer对象
数字特征的缩放
主成分分析
基于过滤器的特征选择
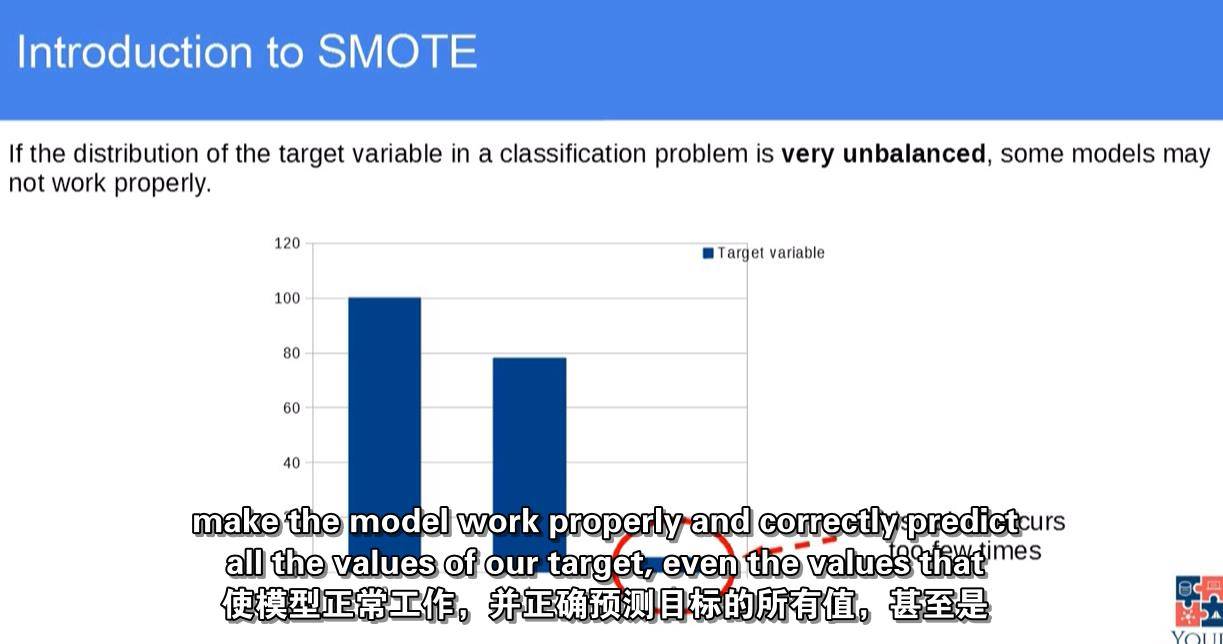
使用SMOTE进行过采样
所有的例子都将使用Python编程语言及其强大的scikit-learn库。将使用的环境是Jupyter,这是数据科学行业的一个标准。本课程的所有部分都以一些实践练习结束,Jupyter笔记本都是可以下载的。

这门课程是给谁的
Python开发者
有抱负的数据科学家
对机器学习和人工智能感兴趣的人
云桥CG资源站 为三维动画制作,游戏开发员、影视特效师等CG艺术家提供视频教程素材资源!
1、登录后,打赏30元成为VIP会员,全站资源免费获取!
2、资源默认为百度网盘链接,请用浏览器打开输入提取码不要有多余空格,如无法获取 请联系微信 yunqiaonet 补发。
3、分卷压缩包资源 需全部下载后解压第一个压缩包即可,下载过程不要强制中断 建议用winrar解压或360解压缩软件解压!
4、云桥CG资源站所发布资源仅供用户自学自用,用户需以学习为目的,按需下载,严禁批量采集搬运共享资源等行为,望知悉!!!
5、云桥CG资源站,感谢您的赞赏与支持!平台所收取打赏费用仅作为平台服务器租赁及人员维护资金 费用不为素材本身费用,望理解知悉!











