


无监督学习:基于PyCaret工作流的异常检测
你会学到什么
了解直觉和异常检测的一些核心概念
提出并制定可以在PyCaret中有效解决的异常检测问题陈述
掌握PyCaret如何通过一些简单的步骤简化工作流程(包括预处理)
管理用于异常检测的简单PyCaret工作流
讲师:达奥林匹亚学习解决方案
4节17节课全长1小时50米
视频:MP4 1280×720 44 KHz |语言:英语+中英文字幕(云桥CG资源站 机译)
2021年12月更新|大小解压后:845M

要求
基本Python和对各种机器学习算法背后的直觉的理解
描述
异常检测识别任何给定情况下的异常值。用于广泛的使用案例-用于识别金融服务中的欺诈,用于制造业中的预测性维护,用于识别社交媒体管理中的假新闻,理解异常检测背后的直觉是每个数据科学家工具箱中的关键工具。
本课程首先介绍异常检测
异常的类型
异常检测用例
一些异常检测算法背后的直觉:隔离森林、局部异常因子和KNN
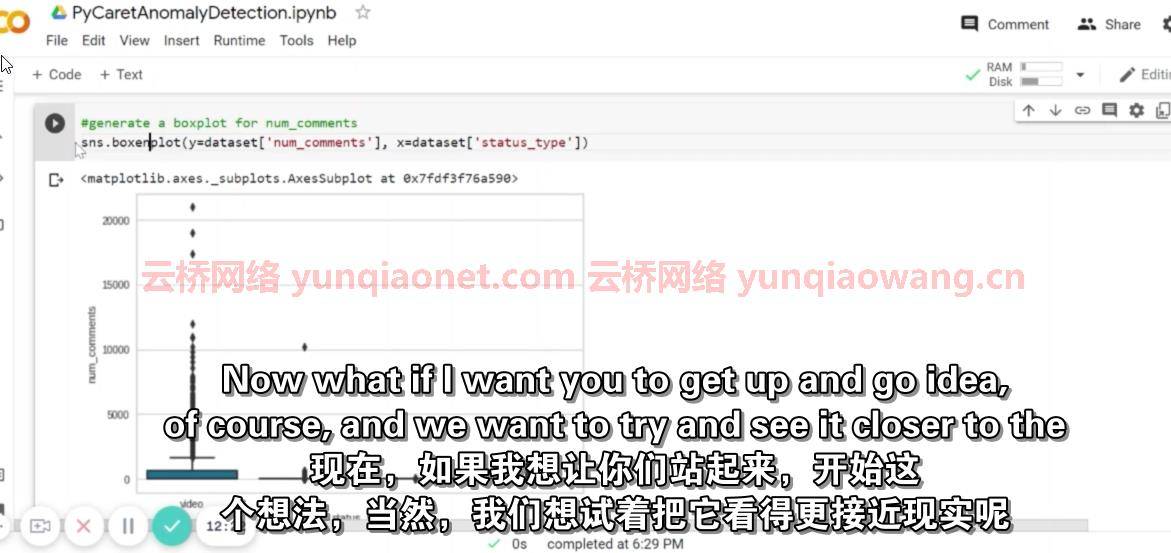
在课程的第二部分,我们将讨论PyCaret工作流
PyCaret库如何简化数据清理和异常检测准备工作
可用的异常检测算法的范围
如何分配模型
如何在PyCaret中可视化异常检测结果?
在课程的第三部分,也是最后一部分,我们使用内置的PyCaret社交媒体数据集(“脸书”数据集)
我们首先使用Python Seaborn进行探索性数据分析
我们根据对帖子/视频/链接和其他内容类型等的反应来识别异常。在这种情况下,问题陈述是为了确定由于反应数量不成比例而可能需要审查的内容。
我们使用一些异常检测模型,并检查数据集中标记为异常的观察值。
我们发现,这些都是收到大量反应的内容类型,不同算法的内容类型和反应类型各不相同。

这门课是给谁的
寻求应用AutoML工具的认证欺诈审查员
分析师希望在银行、健康案例、制造运营中的预测性维护等领域使用深度自动化工具进行异常检测
寻求学习异常检测的低代码机器学习爱好者
初学数据的科学家对AutoML工具和异常检测很好奇
Instructors: DatOlympia Learning Solutions
4 sections • 17 lectures • 1h 50m total length
Video: MP4 1280×720 44 KHz | English + Sub
Updated 12/2021 | Size: 696 MB
Unsupervised learning: Anomaly Detection with PyCaret Workflow
What you’ll learn
Acquire an understanding of the intuition and some core concepts underlying Anomaly detection
Propose and formulate anomaly detection problem statements which can be effectively addressed in PyCaret
Grasp how PyCaret eases the workflow (including preprocessing) through a handful of easy steps
Manage a simple PyCaret workflow for anomaly detection
Requirements
Basic Python and an understanding of the intuition behind various Machine Learning Algorithms
Description
Anomaly detection identifies outliers in any given situation. Used for a wide range of use cases – to identify fraud in financial services, and for predictive maintenance in manufacturing, for identifying fake news in social media management, understanding the intuition behind anomaly detection is a critical tool in every data scientist’s toolbox.
The course begins with an introduction to Anomaly Detection
The types of Anomalies
Anomaly detection use cases
Intuition behind some of the anomaly detection algorithms: Isolation Forest, Local Outlier Factor and KNN
In the second part of the course, we go through a discussion on the PyCaret workflow
How the PyCaret library simplifies data-cleaning and preparation for anomaly detection
The range of anomaly detection algorithms available
How to assign models
How to visualize the results of anomaly detection in PyCaret.
In the third and final part of the course, we work with an inbuilt PyCaret social media dataset (the ‘Facebook’ dataset)
We first undertake exploratory data analysis using Python Seaborn
We identify anomalies based on the reactions to posts/videos/links and other content types etc. In this case, the problem statement is to identify content which might need to be reviewed owing to the disproportionate number of reactions.
We work with a handful of anomaly detection models, and examine the dataset for the observations which are flagged as anomalous.
We discover that these are content types which have received a large number of reactions, and the content types and reaction types vary from algorithm to algorithm.
Who this course is for
Certified fraud examiners looking to apply AutoML tools
Analysts looking to deply AutoML tools for anomaly detection in sectors such as banking, healthcase, predictive maintenance in manufacturing operations
Low-code Machine Learning enthusiasts looking to learn anomaly detection
Beginner data scientists curious about AutoML tools and anomaly detection
云桥CG资源站 为三维动画制作,游戏开发员、影视特效师等CG艺术家提供视频教程素材资源!
1、登录后,打赏30元成为VIP会员,全站资源免费获取!
2、资源默认为百度网盘链接,请用浏览器打开输入提取码不要有多余空格,如无法获取 请联系微信 yunqiaonet 补发。
3、分卷压缩包资源 需全部下载后解压第一个压缩包即可,下载过程不要强制中断 建议用winrar解压或360解压缩软件解压!
4、云桥CG资源站所发布资源仅供用户自学自用,用户需以学习为目的,按需下载,严禁批量采集搬运共享资源等行为,望知悉!!!
5、云桥CG资源站,感谢您的关注与支持!











